The memory consistency model is an important (and complicated) topic that defines how memory loads/stores work in multi-thread(Hart in rv lingo) environment. More detailed explanation of memory consistency can be found in A Primer on Memory Consitency and Cache Coherency
There are several chapters in the spec related to memory model. Listed here for reference
- Chapter 2:
Fenceinstruction - Chapter 3: Zifencei Instruction-Fetch Fence
- Chapter 8: A Standard Extension for Atomic Instructions
- Chapter 14: RVWMO Memory Consistency Modeal
- Chapter 22: Zam Standard Extension for Misaligned Atomics
- Chapter 23: Ztso Standard Extension for Total Store Ordering
RVWMO Link to heading
The following sections define instructions used for explicit sync of RISCV memory model RVWMO. Chapter 14 defines RVWMO formal specifications in detail. I will put couple of important snippets here but probably needs a separate post.
This chapter defines the RISC-V memory consistency model. A memory consistency model is a set of rules specifying the values that can be returned by loads of memory. RISC-V uses a memory model called “RVWMO” (RISC-V Weak Memory Ordering) which is designed to provide flexibility for architects to build high-performance scalable designs while simultaneously supporting a tractable programming model.
Under RVWMO, code running on a single hart appears to execute in order from the perspective of other memory instructions in the same hart, but memory instructions from another hart may observe the memory instructions from the first hart being executed in a different order.
Therefore, multithreaded code may require explicit synchronization to guarantee ordering between mem- ory instructions from different harts. The base RISC-V ISA provides a FENCE instruction for this purpose, described in Section 2.7, while the atomics extension “A” additionally defines load- reserved/store-conditional and atomic read-modify-write instructions.
Memory Ordering Instructions - FENCE Link to heading
Starting with fence which uses 2 operands to define the successor and preceding operations as follows
fence iorw, iorw

The FENCE instruction is used to order device I/O and memory accesses as viewed by other RISC- V harts and external devices or coprocessors. Any combination of device input (I), device output (O), memory reads (R), and memory writes (W) may be ordered with respect to any combination of the same. Informally, no other RISC-V hart or external device can observe any operation in the successor set following a FENCE before any operation in the predecessor set preceding the FENCE. Chapter 14 provides a precise description of the RISC-V memory consistency model.
I see linux kernel using them after the sc.w instruction in the atomic wrappers which should wait for the previous writes.
" sc.w.rl %[rc], %[rc], %[c]\n"
" bnez %[rc], 0b\n"
" fence rw, rw\n"
Zifencei Instruction-Fetch Fence - FENCE.I Link to heading
I can’t write better description than the spec. So, Here it is.
The FENCE.I instruction is used to synchronize the instruction and data streams. RISC-V does not guarantee that stores to instruction memory will be made visible to instruction fetches on a RISC-V hart until that hart executes a FENCE.I instruction
And
FENCE.I instruction ensures that a subsequent instruction fetch on a RISC-V hart will see any previous data stores already visible to the same RISC-V hart
Basically, It ensures that all instructions see the updated memory for all memory operation before the FENCE.i. The spec mentions possible implementations. One of them is doing pipeline flush. This way the core will re-fetch the instruction and pipeline will see the new values.
The FENCE.I instruction was designed to support a wide variety of implementations. A simple implementation can flush the local instruction cache and the instruction pipeline when the FENCE.I is executed
A Standard Extension for Atomic Instructions Link to heading
The A extention defines the following instructions for atomic read/write and operations on memory.

Complex atomic memory operations on a single memory word or doubleword are performed with the load-reserved (LR) and store-conditional (SC) instructions. LR.W loads a word from the address in rs1, places the sign-extended value in rd, and registers a reservation set—a set of bytes that subsumes the bytes in the addressed word. SC.W conditionally writes a word in rs2 to the address in rs1: the SC.W succeeds only if the reservation is still valid and the reservation set contains the bytes being written. If the SC.W succeeds, the instruction writes the word in rs2 to memory, and it writes zero to rd. If the SC.W fails, the instruction does not write to memory, and it writes a nonzero value to rd. Regardless of success or failure, executing an SC.W instruction invalidates any reservation held by this hart.
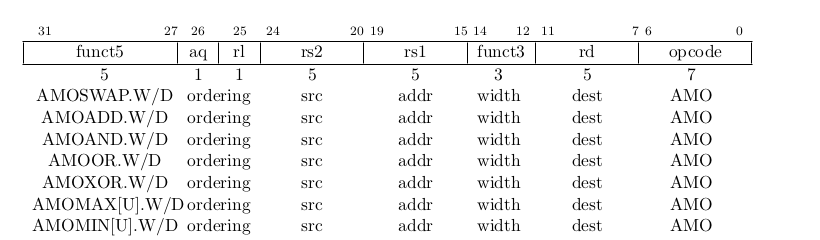
The atomic memory operation (AMO) instructions perform read-modify-write operations for mul- tiprocessor synchronization and are encoded with an R-type instruction format. These AMO in- structions atomically load a data value from the address in rs1, place the value into register rd, apply a binary operator to the loaded value and the original value in rs2, then store the result back to the address in rs1. AMOs can either operate on 64-bit (RV64 only) or 32-bit words in memory. For RV64, 32-bit AMOs always sign-extend the value placed in rd.
Linux Kernel Atomic wrappers Link to heading
Linux kernel defines atomic wrappers in include/asm/atomic.h using all the instruction above.
lr.w and sc.w are used to define atomic add wrapper.
/* This is required to provide a full barrier on success. */
static __always_inline int arch_atomic_fetch_add_unless(atomic_t *v, int a, int u)
{
int prev, rc;
__asm__ __volatile__ (
"0: lr.w %[p], %[c]\n"
" beq %[p], %[u], 1f\n"
" add %[rc], %[p], %[a]\n"
" sc.w.rl %[rc], %[rc], %[c]\n"
" bnez %[rc], 0b\n"
" fence rw, rw\n"
"1:\n"
: [p]"=&r" (prev), [rc]"=&r" (rc), [c]"+A" (v->counter)
: [a]"r" (a), [u]"r" (u)
: "memory");
return prev;
}
In the same file, AMO wrappers are defined with macro ATOMIC_OP
#define ATOMIC_OP(op, asm_op, I, asm_type, c_type, prefix) \
static __always_inline \
void arch_atomic##prefix##_##op(c_type i, atomic##prefix##_t *v) \
{ \
__asm__ __volatile__ ( \
" amo" #asm_op "." #asm_type " zero, %1, %0" \
: "+A" (v->counter) \
: "r" (I) \
: "memory"); \
}
ATOMIC_OPS(add, add, i)
ATOMIC_OPS(sub, add, -i)
ATOMIC_OPS(and, and, i)
ATOMIC_OPS( or, or, i)
ATOMIC_OPS(xor, xor, i)
And finally,fence.i is used in head.S at the start of _start_kernel
ENTRY(_start_kernel)
/* Mask all interrupts */
csrw CSR_IE, zero
csrw CSR_IP, zero
#ifdef CONFIG_RISCV_M_MODE
/* flush the instruction cache */
fence.i